As mentioned in last blog, scaling model size and data size is a key to improve performance of transformer-based models. However, collecting large-scale data is not always an easy task. In this blog, I will introduce some multimodal learning methods, which expand the training data to other modals.
Table of contents
- Table of contents
- Multimodal Learning
- CLIP
- SAM
- BLIP and BLIP-2
- ImageBind
- LanguageBind
- LLaVA
- Conclusion
- References
Multimodal Learning
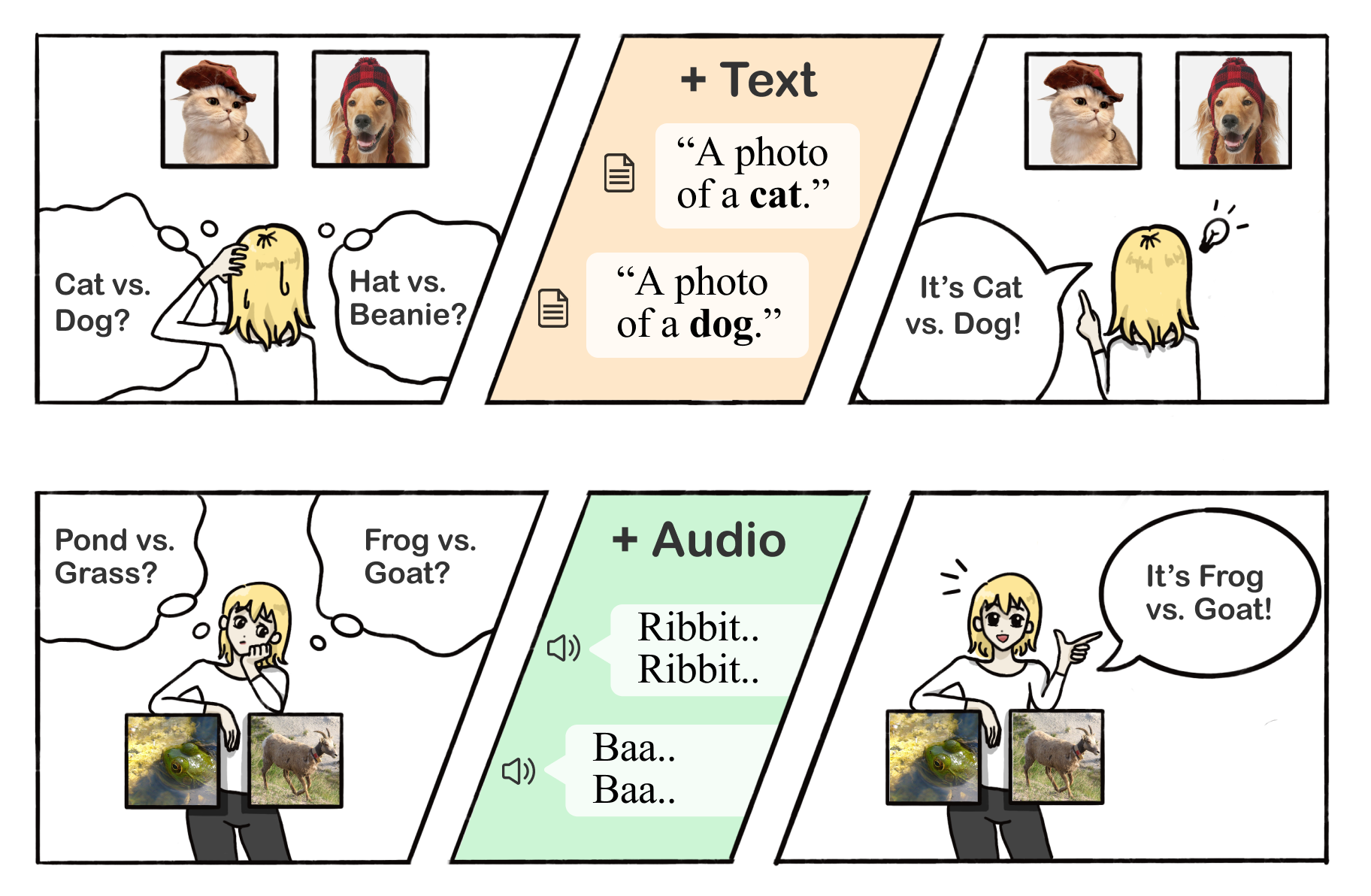
image source: Multimodality Helps Unimodality
Owing to dataset bias, a majority of unimodal models find it difficult to generalize effectively on new tasks or domains. Take, for instance, image classification models that are trained on ImageNet and struggle to classify blurred images. However, if we obtain the audio corresponding to the blurred image, we can potentially predict the class of the blurred image with greater ease (such as a car). As depicted in the figure presented above, we are able to utilize additional text or audio information to enhance the discriminatory capacity.
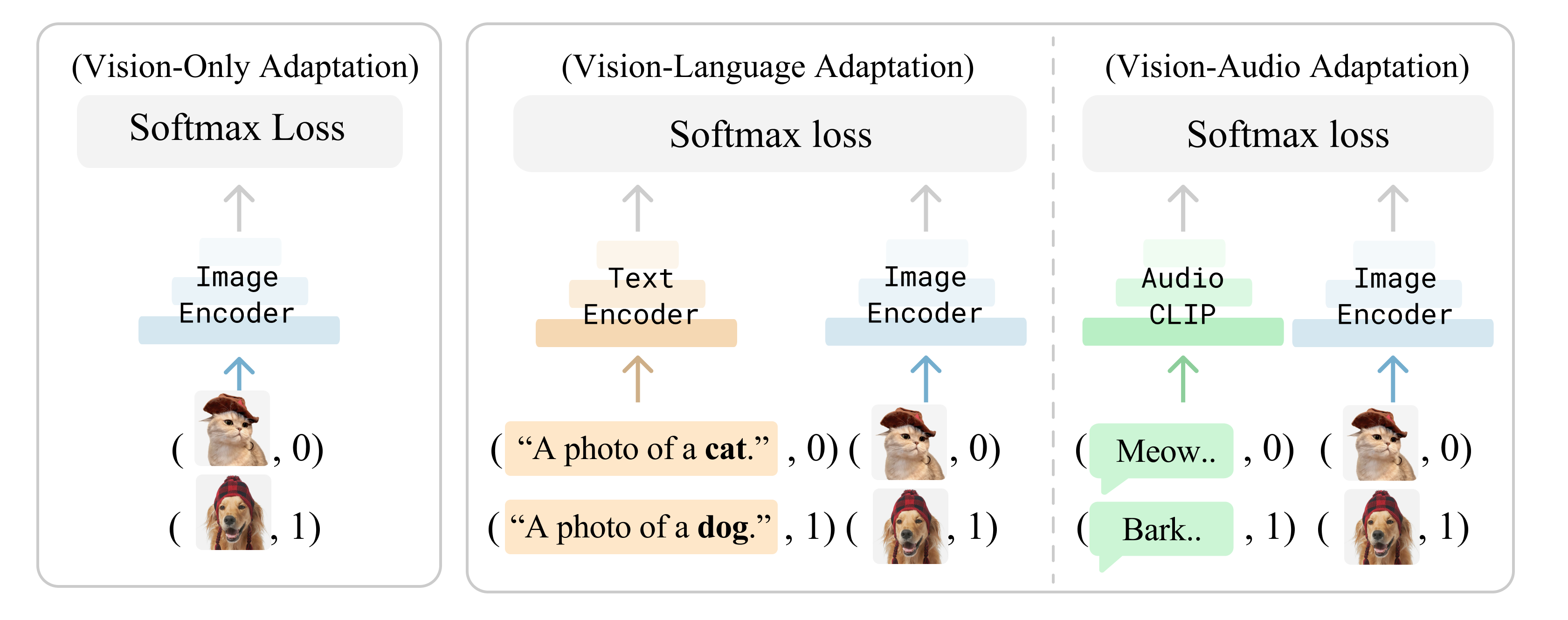
image source: Multimodality Helps Unimodality
To employ multimodal information, contrastive learning and transformer architecture are always a good choice. With contrasive learning, we can learn a representation that is invariant to the modality and align multiple modals. Transformers are able to compress multimodal information into a same semantic representation.
CLIP

image source: CLIP
SAM

image source: segment-anything
BLIP and BLIP-2

image source: LAVIS
ImageBind
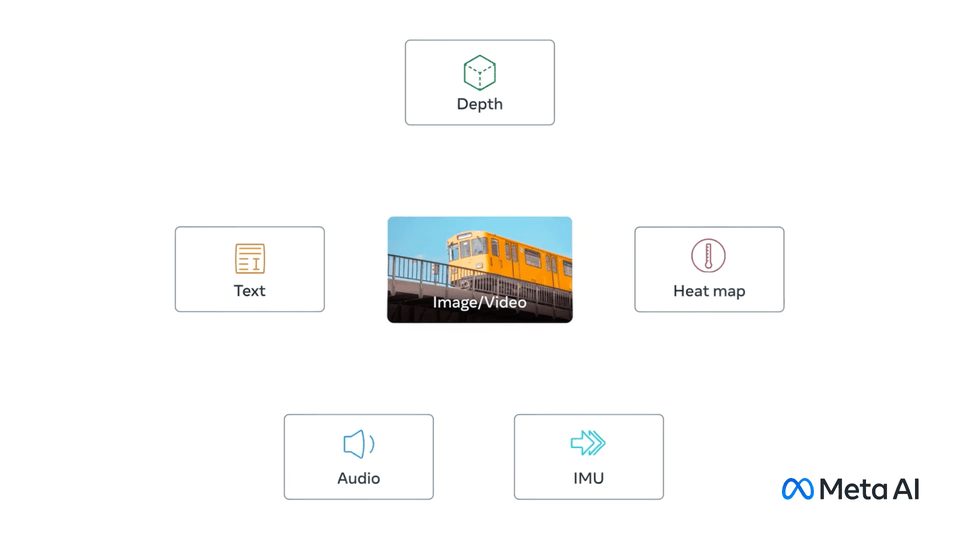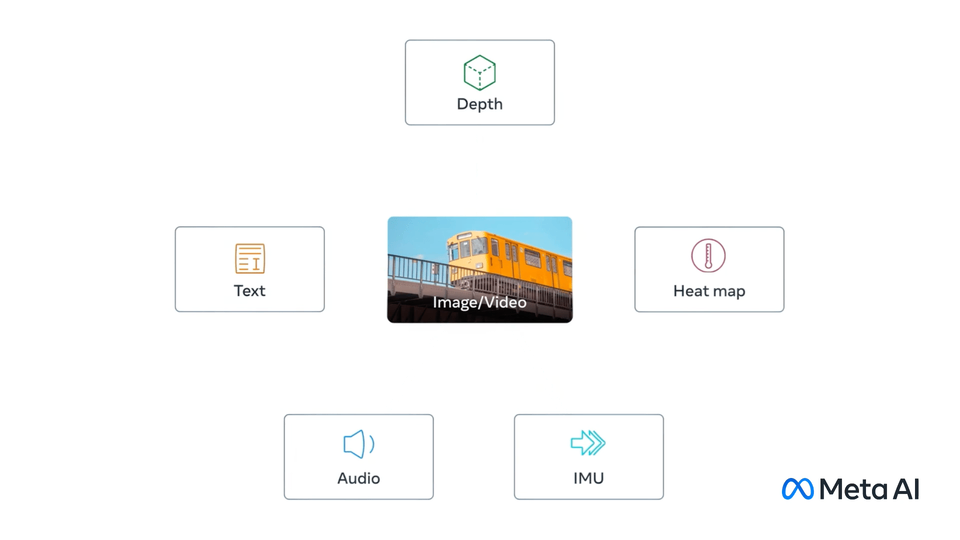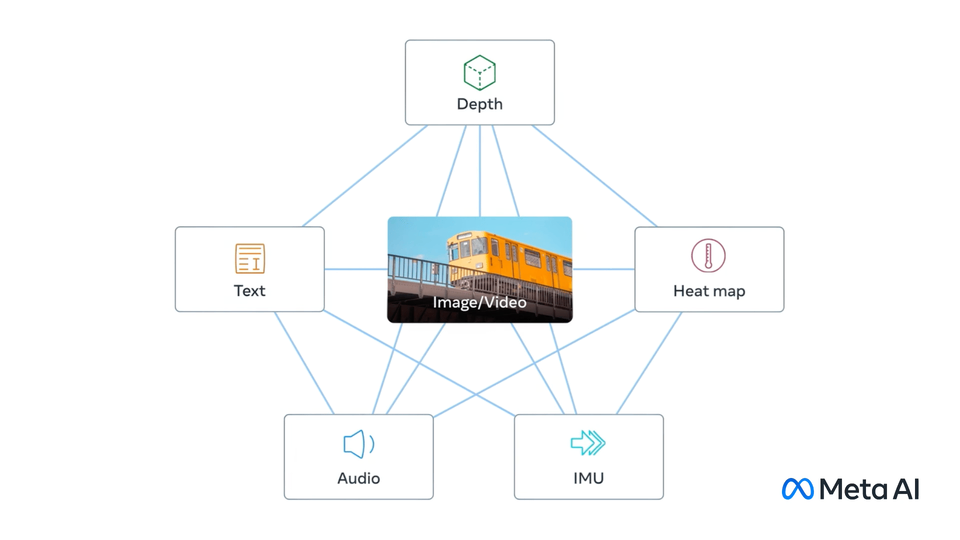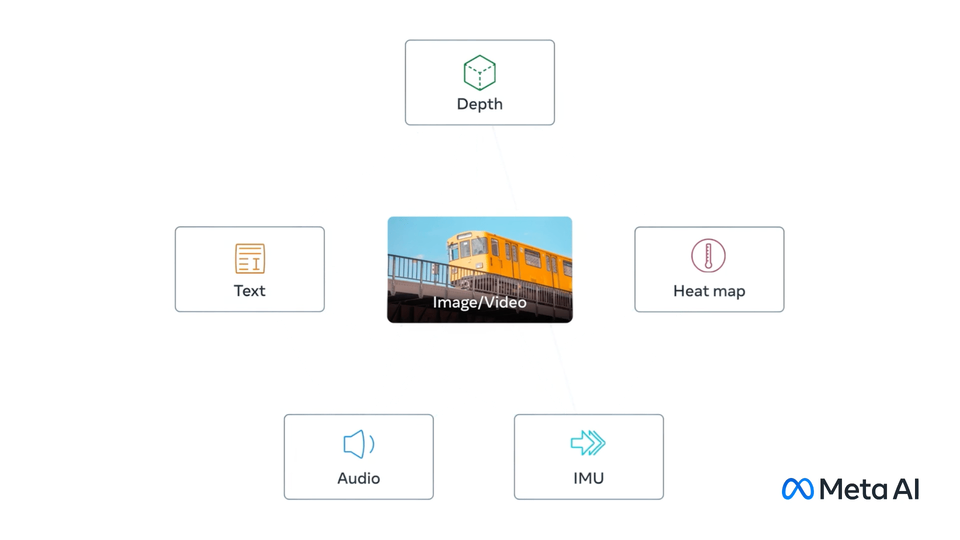
image source: ImageBind
LanguageBind

image source: LanguageBind
LLaVA

image source: LLaVA
Conclusion
Unlike training with more data, multimodal learning is an more promising direction to improve performance. However, it is still a challenging task to fusion unpaired data from different modals.
References
- [ICML’21] Learning Transferable Visual Models From Natural Language Supervision
- [ICCV’23] Segment Anything
- [ICML’22] BLIP: Bootstrapping Language-Image Pre-training for Unified Vision-Language Understanding and Generation
- [ICML’23] BLIP-2: Bootstrapping Language-Image Pre-training with Frozen Image Encoders and Large Language Models
- [CVPR’23] ImageBind: One Embedding Space To Bind Them All
- [ICLR’24] LanguageBind: Extending Video-Language Pretraining to N-modality by Language-based Semantic Alignment
- [NeurIPS’23] Visual Instruction Tuning
- [CVPR’24] Improved Baselines with Visual Instruction Tuning
- [CVPR’23] Multimodality Helps Unimodality: Cross-Modal Few-Shot Learning with Multimodal Models