Transformer architecture has become the the de-facto standard for vision and natural language tasks. In this blog, we will discuss the key components of the transformer architecture and how it enables efficient and effective representation learning for both vision and natural language tasks.
Table of contents
- Table of contents
- Transformers and self-attention mechanism
- Large language models
- Vision transformers
- Conclusion
- Reference
Transformers and self-attention mechanism
Transformers are based on the self-attention mechanism. The self-attention mechanism is a special type of attention mechanism that allows the model to focus on different parts of the input sequence or input image, and it is used to capture the relationships between different parts of the input. Compared with convolutional neural networks and recurrent neural networks, transformers are more efficient and can handle long-range dependencies. Let us illustrate the self-attention mechanism with a simple example.
Self-attention mechanism


![]()
image source: The Illustrated Transformer
As illustrated in the figures above, the self-attention mechanism enables a global receptive field and thus handle long-range dependencies. For example, the attention score of it_ is computed based on the similarity between it_ and all other input tokens.
But this mechanism is too costly for high-resolution images or long input texts. Assume the input sequence has $n$ tokens, then the self-attention mechanism needs to compute $n^2$ attention scores. Thus, how to preserve the global information while reducing the unnecessary computation is a hot and challenging problem.
Large language models
Based on transformers, large language models (LLMs) have been developed and are widely used in various NLP applications. Prior to LLMs, the first transformer based language models are BERT series [1]. They built a simple but effective encoder-decoder architecture with transformers. Then, GPT series [2] have proposed and shown that scaling LLMs can obtain some unseen capabilities (such as few-shot and zero-shot learning). Different from BERT, GPT series use a decoder-only architecture to generate texts.
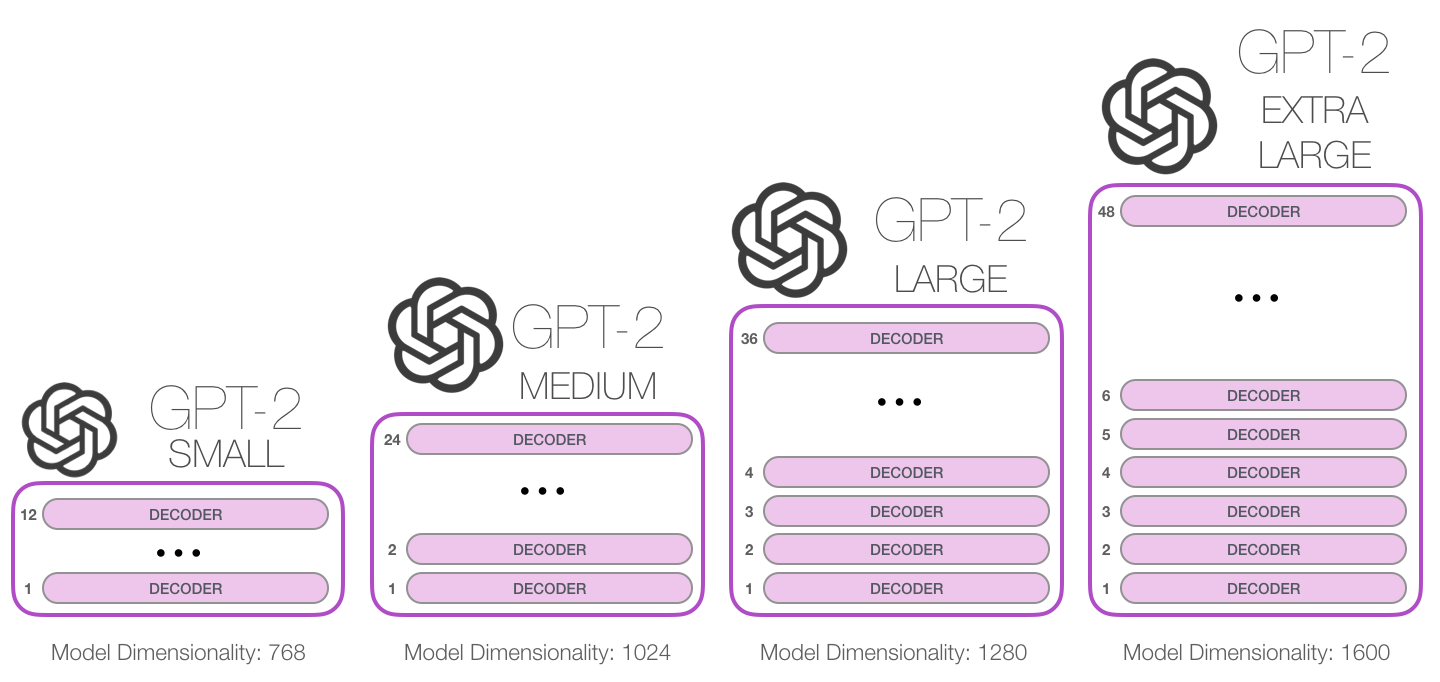
![]()
![]()
image source: The Illustrated GPT-2
To get a best-practice of training LLMs, the scaling law [3] is proposed and shown that the performance of LLMs can be improved by increasing the model size and the datasize together.
In sum, scaling law can be formulated as follows:
\[\left\{\begin{array}{l} C= C_{0}\cdot N\cdot D \\ L=\frac{A}{N^{\alpha}} + \frac{B}{D^{\beta}} + L_{0} \end{array}\right.\]where the variables are
- $C$ is the cost of training the model, in FLOPS.
- $N$ is the number of parameters in the model.
- $D$ is the number of tokens in the training set.
- $L$ is the average negative log-likelihood loss per token (nats/token), achieved by the trained LLM on the test dataset.
- $L_{0}$ represents the loss of an ideal generative process on the test data.
- $\frac{A}{N^{\alpha}}$ captures the fact that a Transformer language model with $N$ parameters underperforms the ideal generative process.
- $\frac{B}{D^{\beta}}$ captures the fact that the model trained on $D$ tokens underperforms the ideal generative process.
Since there are 4 variables related by 2 equations, imposing 1 additional constraint and 1 additional optimization objective allows us to solve for all four variables. In particular, for any fixed $C$, we can uniquely solve for all 4 variables that minimize $L$. This provides us with the optimal $D_{opt}(C)$, $N_{opt}(C)$ for any fixed $C$.
\[N_{opt}(C) = G(\frac{C}{C_{0}}) \\ D_{opt}(C)=G^{-1}(\frac{C}{C_{0}})^{b}\]where $G=\frac{\alpha A}{\beta B}^{\frac{1}{\alpha+\beta}}$, $a=\frac{\beta}{\alpha+\beta}$ and $b=\frac{\alpha}{\alpha+\beta}$.
Vision transformers
Driven by scaling capabilities of transformers, vision transformers (ViTs) [4,5,6] have been proposed and shown strong results on large-scale benchmarks. Unlike NLP tasks, most vision tasks are discriminative instead of generative. Thus, the encoder-only model archiecture are widely used in ViTs. To achieve the accurate discriminative performance, some features of convolution models (e.g., translation invariance and hierarchical feature extraction) are integrated with recent SOTA ViTs [5].

image source: vision transformer
![]()
image source: swin transformers
Conclusion
In this blog, we have introduced the basic concepts of transformers and the scaling laws for LLMs. We also discussed the recent progress of vision transformers.
Reference
- [NeurIPS’17] Attention Is All You Need, Google Research
- [NeurIPS’20] Language Models are Few-Shot Learners, OpenAI
- [arXiv 2020] Scaling Laws for Neural Language Models, JUH and OpenAI
- [ICLR’20] An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale, Google Research
- [ICCV’21] Swin Transformer: Hierarchical Vision Transformer using Shifted Windows, Microsoft Research Asia
- [ECCV’22] End-to-End Object Detection with Transformers, Meta AI